Logical Memory and Physical Memory
A computer’s physical memory (RAM) is hardware composed of storage units called words. A “word” is a fixed unit of data size, commonly 1 word = 4 bytes (refer to the table below). A physical address denotes the location of a specific word within an $n$-sized memory space.
| Value | Unit | = | Value | Unit |
|---|---|---|---|---|
| 1 | Word | = | 4 | Bytes |
| 1 | Byte | = | 8 | Bits |
A logical address space is an abstraction of physical memory. It consists of an abstract range of memory addresses from 0 to $m-1$, where $m$ is the size of the logical space. A logical address is an identifier for any specific word within this range.

As shown above, at the hardware level, we have memory allocated with a space size from 0 to 14 (in words). Remember virtualization from our first review? The operating system virtualizes a logical address space for each program, all starting from 0. Therefore, the logical address space doesn’t “exist” physically in RAM; the actual data for these programs is initially stored on disk. This approach offers several benefits:
- Security and Isolation: Without this logical layer, processes would read and write directly to physical memory, posing a severe security risk due to lack of isolation. Through logical partitioning, processes are unaware of each other’s existence, ensuring process security.
- Efficiency: With this layer, the OS can move processes that haven’t been used for a long time back to the disk (swapping). This allows for more efficient scheduling of memory usage (note in the diagram, Process 1 does not need to be stored contiguously).
- Abstraction: Through virtualization, users do not need to manually design and manage memory allocation. A process perceives that it is accessing actual memory space, and this space appears infinitely large to the process.
Program Transformation
A source module is a program written in a programming language, or rather a component of a program. It must be transformed into executable machine code by a compiler or interpreter.
An object module is the machine language output obtained after compiling the source code. An object module can run individually or be linked with other modules using a linker to create a single load module.
A load module consists of one or more modules formed into a program that can be loaded into memory and executed.

Relocation and Address Binding
Since the physical addresses of a program cannot be determined until it is moved into a load module, compilers and linkers assume the logical address space starts at 0. During each step of program transformation, the logical addresses and data referenced in instructions might be changed. Only in the final step, during program loading, can the program be bound to its physical addresses.
Program relocation is the process of mapping a program component from one address space to another. Relocation can be a conversion between two logical address spaces, or a mapping from a logical address space to physical address space.
Static relocation means binding all logical addresses to physical addresses before the process is executed.
Dynamic relocation delays the binding of logical addresses to physical addresses until that part of the code needs to be executed.
Consider this line of code:
1 | mov R1, 200 |
Under static relocation, once the program is loaded into memory, this address will be translated into the allocated physical address immediately upon loading:
1 | mov R1, 1200 // Assuming base address is 1000 |
Conversely, dynamic relocation does not alter this part of the code; instead, the translation occurs during execution.
Implementation of Dynamic Relocation
Registers within the CPU can be used for relocation. Most programs consist of three parts: code, static data, and dynamic data. A simple memory management method is to treat these three parts as a whole, meaning they are placed in contiguous memory space. Dynamic relocation can be implemented using a relocation register, whose value is the physical starting address of the program. This register’s address is invoked whenever address translation is needed during subsequent code execution.

Let’s look at the example above. There is a process in memory. At a certain moment, it is allocated to physical memory starting at position 500, so our Relocation Register (RR) holds 500. When we perform the operation load R1, 100 (moving the value at logical address 100 to R1), it actually fetches content from the physical memory space at address (RR + 100), which is 600. Later, after memory compaction, the process is moved to start at physical address 100. Now, when performing load R2, 20, it loads data from address (100 + 20), which is 120.
Another more flexible method is to separate the three parts (code, static data, dynamic data), placing each in a different memory address. Then, use three distinct relocation registers to keep track of the location of each part.
Free Space Management
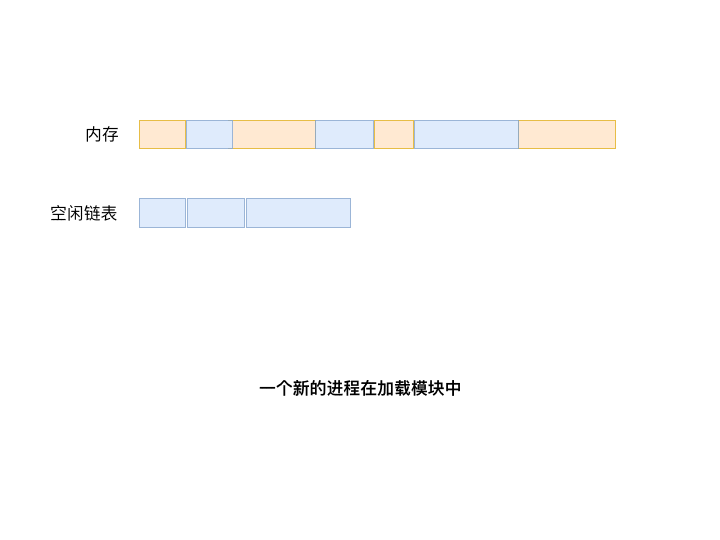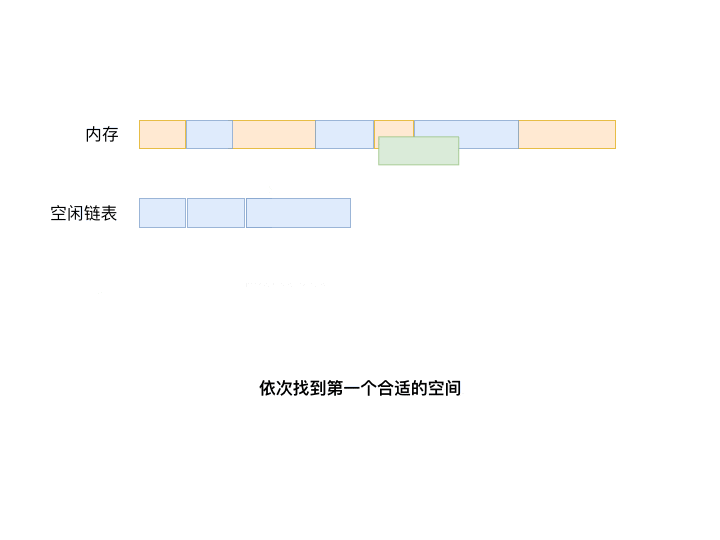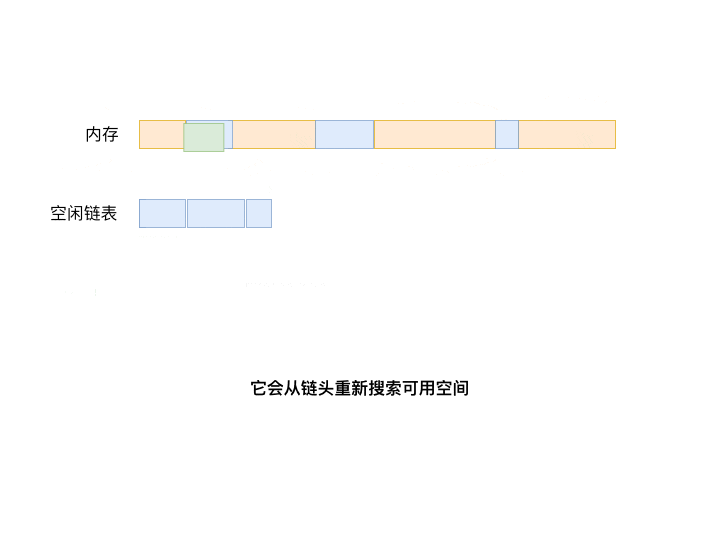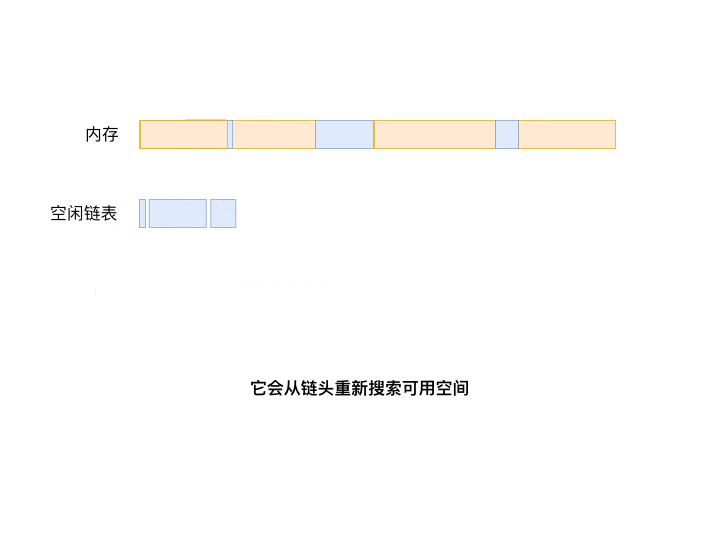
As processes run and terminate, and because memory space is finite, they are constantly being moved in and out. It would be a waste not to fully utilize the entire memory space. Furthermore, some processes require more space after executing to a certain point; at this stage, the system needs to move them into a larger empty slot. We call these slots holes (free partitions). Therefore, an operating system must monitor the usage of memory space. Generally, when a program needs to be loaded into memory, the operating system uses a linked list to find the best available hole for the program. We call that linked list that tracks free partitions the free list.

The diagram above shows a program P searching for available space through the free list. There are multiple algorithms for finding memory space for a program:
First Fit Algorithm
The First Fit algorithm always starts searching from the first element of the list until it finds the first hole that satisfies the process size requirement.
Next Fit Algorithm
Compared to First Fit which searches from the beginning, the Next Fit algorithm starts its search from the location where space was last allocated.

Best Fit Algorithm
This algorithm traverses the entire list to find the smallest hole that can accommodate the program.
Worst Fit Algorithm
This algorithm is the opposite of Best Fit; it always searches for the largest available hole for the program to use.
Note: The free list automatically adjusts every time a process is loaded into or removed from memory.
Managing Memory Shortages
Memory Fragmentation and the 50% Rule
External memory fragmentation refers to insufficient available memory space caused by having many free partitions that are individually too small. As shown below, because each free block is very small, program P cannot be loaded into memory; however, if memory were planned reasonably, P could actually fit.

The 50% Rule states that if the probability of finding an exact fit for a loading program approaches 0, one-third of the memory space will be free partitions (holes), while the remaining two-thirds will be space used by other programs. This prediction fluctuates, but generally works out to:
$$ \text{Number of Free Partitions} = 0.5 \times \text{Number of Occupied Memory Blocks} $$
In other words, for every free partition that appears in memory, there are two occupied memory blocks.
Swapping and Memory Compaction
When no single free partition is large enough to accommodate a program being loaded, there are two solutions:
- Swapping: Temporarily moving a program block out of memory space. This program is retained on the disk and moved back later.
- Memory Compaction: Memory compaction utilizes a systematic approach to move blocks within memory. Generally, this movement is towards one end, which allows smaller modules to be consolidated into a large one, leaving larger continuous space for remaining free partitions.
Shared Modules
In the section on load modules, we mentioned that many programs are combined into a single large program block via a linker. To fully utilize memory space, a sharing mechanism is introduced in memory management. When multiple programs need to use a certain module, the system allows them to call the exact same module in memory.
Paging
A page is a fixed-size block defined between two adjacent logical addresses.
A page frame is a fixed-size block defined between two adjacent physical addresses, identified by a number. A page frame is the smallest unit of data in paging memory management.
A page table is an array used to record the pages in logical address space and the corresponding page frames they map to in physical memory space.

Logical Address and Physical Address
The size of the address space exists in the form $2^n$, where $n$ is the number of bits required to uniquely address the space. When the address space is divided into pages, the page size is $2^k$, where $k$ is the number of bits needed to represent the offset within each page. The remaining $n-k$ bits determine the number of pages: $2^{n-k}$.
By dividing the memory address into two parts, the first $n-k$ bits typically represent the page number, and the remaining $k$ bits are used to represent the offset $w$ within that page.
Assume our address is 6-bit; we will need six binary digits to represent memory addresses $(2^6 = 64)$. Assume the page size is 8; we will need 3 bits to record the offset $(2^3 = 8)$. The remaining three bits will be used to record the page number.

Note that P1, P2, P3 in the diagram above do not represent “process,” but rather “page.” Depending on the paging scheme, logical memory page numbers may map to different physical locations, but the offset within each page always remains the same.

In the diagram above, logical page number 111 is mapped to physical page frame 0111, but the offset is always between 000-111.
Address Mapping
The operating system needs to match logical memory addresses $(p, w)$ to physical memory addresses $(f, w)$. Here, $p$ and $f$ represent page and page frame respectively, and $w$ represents the offset. Mapping from logical memory to physical memory involves the following steps:
- Receive a logical address $(p, w)$. Locate entry $p$ in the page table.
- Read the corresponding page frame $f$ associated with page $p$.
- Combine $f$ with the offset $w$ to find the corresponding physical address $(f, w)$.
Internal Fragmentation and Boundary Monitoring
Paged storage dictates that page size and page frame size must be identical, so that all pages can find a corresponding page frame without generating free partitions outside of pages. This avoids the creation of external fragmentation. However, storage systems typically allow only one size of page to exist. When a page is not fully utilized, internal fragmentation occurs.
For security reasons, when a program is loaded into memory or when address translation is required, it must be guaranteed that a program’s addresses do not exceed its boundaries.

The diagram above shows a program occupying 3 pages, where the third page is only partially used (internal fragmentation). The operating system must ensure that the space accessible to this program is only the first half of page 1, page 2, and the boundary (dashed line) of page 3.
Segmentation and Paging
In purely paged storage, all program code, data, stacks, and other data structures are placed across a set of contiguous pages. The size of each part of the program varies, and the boundaries of these various parts do not align perfectly with page boundaries. For example, the program boundary might be at 011, 001, while the page boundary is at 011, 111. Because these boundaries are inconsistent, sharing and protection between programs in logical space cannot be guaranteed.
Segmentation is a method used to solve this problem; it provides variable logical spaces for each process. Correspondingly, segmentation also requires a segment table to implement the mapping between logical memory and physical memory.

Address Translation
Like paging, segmented storage divides each logical address into two parts. The steps for the operating system to translate a virtual address to a physical address are as follows:
- Input a logical address $(s, w)$.
- Find segment $s$ in the segment table to locate the corresponding physical segment starting address
saand its sizesze. - If offset $w > sze$, reject the address request (segmentation fault).
- Otherwise, access the corresponding physical address at $(\text{sa} + w)$.
Segmentation + Paging (Paged Segmentation)
The advantage of segmented storage is the ability to create multiple variable address spaces, while the strength of paging is the ability to place any page into any page frame in memory. To leverage the strengths of both, we can combine these two methods.
The logical address space contains multiple variable segments, but each segment is divided into pages of equal size. Unlike using paging or segmentation alone, this time we must divide the address into three parts: segment number, page number, and offset $(s, p, w)$. A physical address is still divided into two parts: frame number and offset $(f, w)$.
Each process has a segment table, and each entry in that table points to a corresponding page table. To translate an address, the operating system performs the following:
- Input a logical address $(s, p, w)$. Use the segment table to find the corresponding page table for segment $s$.
- If $(p, w)$ on the page table exceeds the declared size of the segment, reject the access.
- Otherwise, access that page table to find the frame $f$ corresponding to page $p$. Then, locate the offset $w$ within that page frame $f$.
This memory management approach combining both methods is known as paged segmentation.
Translation Lookaside Buffer (TLB)
Whether using paging or segmentation, they both frequently require accessing segment tables and page tables to read and write memory information. This translation process must run at high speed to ensure programs run smoothly. Consequently, the Translation Lookaside Buffer (TLB) was invented. This is a high-speed associative cache module used to record recent address translations. When a logical address $(s, p, w)$ is translated into a physical address $(f, w)$, the TLB stores the mapping between $(s, p)$ and $f$. When another address needs to be accessed that has the same segment and page as the previous address, the TLB quickly retrieves the stored frame $f$, adds the new offset $w’$, and accesses the address $(f, w’)$.