这篇文章由英文翻译并优化,阅读原文章.
搜索 (Searching)
简介
问题 (搜索):
给定: 一个元素集合,$A = {a_1, a_2, . . . , a_n}$ 以及一个关键字元素 $e_k$。
输出: 集合 $A$ 中与 $e_k$ 匹配的元素 $a_i$。
变体:
• 查找第一个匹配的元素
• 查找最后一个匹配的元素
• 查找元素的索引 (Index)
• 基于关键字 (Key) 与基于“相等” (Equality)
• 查找所有匹配的元素
• 查找极值元素
• 如何处理搜索失败(元素不存在)?
注意:该问题是以通用术语陈述的;在实际应用中,搜索可能会在数组、列表、集合,甚至解空间(针对优化问题)上进行。
线性搜索 (Linear Search)
• 解决该问题的一个基础且直接的方法是线性搜索算法(也称为顺序搜索)。
• 基本思想:遍历集合中的每个元素,与关键字 $e_k$ 进行比较。
伪代码

示例
考虑下表中的整数数组。在以此数组上运行线性搜索算法,查找以下关键字:20, 42, 102, 4。
| 索引 (index) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 元素 (element) | 42 | 4 | 9 | 4 | 102 | 34 | 12 | 2 | 0 |
分析
顾名思义,线性搜索的复杂度是线性的。
- 输入:元素集合 A
- 输入大小:$n$(共有 $n$ 个元素)
- 基本操作:第 2 行中与关键字的比较
- 最好情况:我们立即找到元素,进行 $O(1)$ 次比较
- 最坏情况:我们找不到它,或者在最后一个元素找到它,进行 $n$ 次比较,效率为 $O(n)$
- 平均情况(省略细节):预期的比较次数为 $\frac{n}{2} \in O(n)$
二分搜索 (Binary Search)
一种更高效的搜索方式是二分搜索算法。其基本思想如下。在假设集合已排序的前提下,我们可以:
• 检查中间元素:
- 如果中间元素正是我们要找的,完成
- 如果我们要找的元素小于中间元素,它一定在列表的下半部分
- 否则,它一定在列表的上半部分
• 在任何一种情况下:列表都被(至少)切分成了两半;我们可以对子列表重复该操作。
• 我们继续,直到:找到与关键字匹配的元素,或者子列表为空。
伪代码:递归 (Recursive)

伪代码:迭代 (Iterative)

示例
考虑下表中的整数数组。在该数组上运行二分搜索算法,查找以下关键字:20, 0, 2000, 4。
| 索引 (index) | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 元素 (element) | 0 | 2 | 4 | 4 | 9 | 12 | 20 | 21 | 23 | 32 | 34 | 34 | 42 | 102 | 200 | 1024 |
分析
输入:元素集合 A
输入大小:$n$(元素数量)
基本操作:比较(针对每个“中间”元素执行一次)
分析:
• 设 $C(n)$ 为二分搜索在大小为 $n$ 的集合上进行的(最大)比较次数
• 在每次递归调用中,进行一次比较,加上下一次递归调用的比较次数
• 列表被切分成了两半;因此下一次递归调用将贡献 $C(\frac{n}{2})$
• 总计:$C(n) = C(\frac{n}{2}) + 1$
• 根据主定理 (Master Theorem) 的情况 2,二分搜索的效率为 $O(\log n)$另一种视角:
• 我们从一个大小为 $n$ 的列表开始
• 在第一次迭代后,它被减半为:$\frac{n}{2}$
• 在第二次后,它再次减半:$\frac{n}{2^2}$
• 在 $i$ 次这样的迭代后,大小为: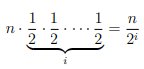
• 当列表大小为 1 时算法终止(实际上是 0,但我们将单独处理最后一次迭代):$\frac{n}{2^i} = 1$
• 解得 $i = \log n$,因此迭代次数为 $O(\log n)$
将二分搜索与线性搜索进行对比:假设我们要搜索一个拥有 1 万亿 ($10^{12}$) 条记录的数据库
• 线性搜索:大约需要 $10^{12}$ 次比较
• 二分搜索:大约 $\log_2(10^{12}) \approx 40$ 次比较
进一步假设一个列表最初有 $n$ 个元素,并且其大小翻倍;那么
• 线性搜索:在新列表上需要两倍的比较次数
• 二分搜索:$\log_2(2n) = \log_2(2) + \log(n) = \log(n) + 1$;也就是说,仅比以前多一次比较
• 二分搜索需要预付 $O(n \log n)$ 的成本进行排序(如果维护了顺序,则更少)
• 如果只进行一次搜索,不需要排序,直接使用线性搜索
• 如果重复进行,即使是少量,比如进行了 $O(\log n)$ 次搜索,排序并使用二分搜索也是值得的
在 Java 中搜索 (Searching in Java)
线性搜索
1 | /** |
二分搜索
1 | /** |
1 | /** |
防止算术错误 (Preventing Arithmetic Errors)
计算新中间索引的代码行,例如:
1 | int middle_index = (high + low)/ 2; |
在处理非常大的数组时,容易出现算术错误。特别是,如果变量 high 和 low 的总和超过了带符号 32 位整数所能持有的最大值 $(2^{31} - 1 = 2, 147, 483, 647)$,那么在除以 2 之前就会发生溢出 (Overflow),从而导致一个(潜在的)负数。
一种解决方案是使用 long 整数代替,这将防止溢出,因为它能够处理任何大小的数组(数组实际上限制为 32 位带符号整数(实际上考虑到对象的一小部分内存开销,还要稍小一些))。
另一种解决方案是使用不引入此溢出的操作。例如,
$$\frac{l+h}{2}=l+\frac{(h-l)}{2}$$
但右侧将不易发生溢出。因此代码,
1 | int middle_index = low + (high - low)/ 2; |
将有效。
在 Java 中搜索:正确地做 (Doing It Right)
在实际应用中,我们不重复造轮子:我们不为每种类型和每种排序顺序编写自定义搜索函数。
相反,我们:
- 使用语言提供的标准搜索函数
- 使用 Comparator 进行配置 (Configure),而不是编写代码 (Code)
• 内置函数要求正确覆盖equals()和hashCode()方法
• 线性搜索:List.indexOf(Object o)
• 二分搜索:intCollections.binarySearch(List list, Object key)
– 使用二分搜索算法在指定列表中搜索指定对象
– 返回key出现的索引
– 如果未找到,返回一个负值
– 要求列表包含具有自然顺序 (Natural Ordering) 的元素
• 二分搜索:intCollections.binarySearch(List list, Object key, Comparator c)
– 使用二分搜索算法在给定列表中搜索指定对象
– 使用提供的Comparator来确定顺序(不使用equals()方法)
• 数组的二分搜索:Arrays.binarySearch(T[] a, T key, Comparator<? super T> c)
示例
1 | ArrayList < Student > roster = ... // 初始化 roster 列表 |