快速排序 (Quick Sort)
伪代码


算法分析
• 快速排序的性能高度依赖于划分(Partitioning)的均匀程度。
• 划分的均匀程度取决于基准值(Pivot)的选择。
最好情况 (Best Case)
• 理想的基准值选择:始终选择中位数元素。
• 将列表均匀地划分为两个相等的子部分。
• 对大小约为一半的子列表进行两次快速排序递归调用。
• 划分过程需要线性的比较次数。
• 递推关系式:$$C(n)=2C(\frac{n}{2})+n$$
• 根据主定理(Master Theorem),时间复杂度为 $O(n \log n)$。
最坏情况 (Worst Case)
• 最差的基准值选择:始终选择极值元素(最大或最小)。
• 将列表划分为一个空列表和一个大小为 $(n - 1)$ 的子列表。
• 只需要进行一次递归调用,但针对的是大小为 $(n - 1)$ 的列表。
• 递推关系式:$$C(n) = C(n - 1) + n$$
• 通过代入法求解可得时间复杂度为 $O(n^2)$。
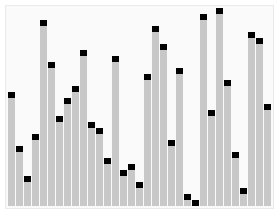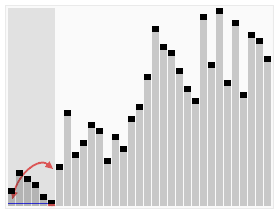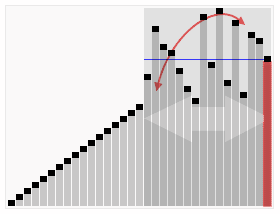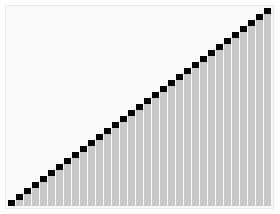
平均情况 (Average Case)
• 即使列表只是按固定比例(如常数比例)分割,时间复杂度仍为 $O(n \log n)$。
• 严谨的平均情况分析表明比较次数约为 $$C(n) \approx 1.38n \log n$$
• 依然属于 $O(n \log n)$ 级别。
基准值选择 (Pivot Choice)
基准值的选择极大地影响性能;常用的策略包括:
• 三数取中 (Median-of-Three):在三个元素(如首、尾、中)中选择中位数。
– 保证基准值的选择永远不会导致最坏情况。
– 但不能从理论上保证 $\Theta(n \log n)$。
• 随机元素 (Random Element):随机选择一个索引作为基准值元素。
– 保证平均运行时间为 $\Theta(n \log n)$。
– 随机选择基准值需要额外的开销。
• 线性时间中位数查找 (Linear Time Median Finding)。
– 存在一种可以在 $\Theta(n)$ 时间内找到 $n$ 个对象中位数的算法。
– 在所有情况下都能保证 $\Theta(n \log n)$。
– 算法复杂,涉及递归,且有巨大的额外开销(Overhead)。
代码示例
1 | private static void quickSort (int a [] , int left , int right ) { |
1 | public static int partition (int a [] , int left , int right ) |
1 | void swap (int *a , int * b ) |
一个包含非递归 C 语言实现的优秀教程:http://alienryderflex.com/quicksort/